# Java 核心
# 集合
# hashmap
- 实现
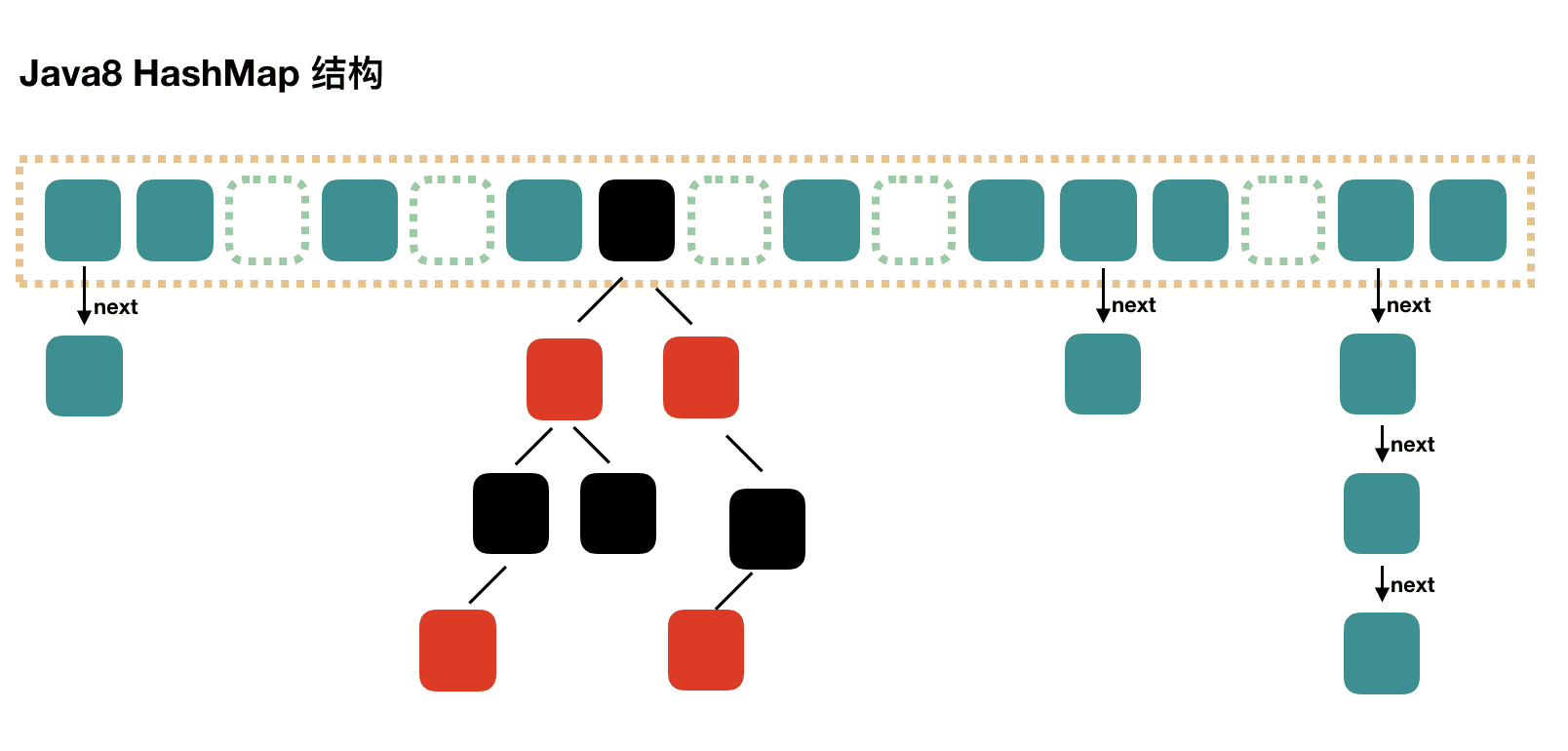
1.7是数组+链表
1.8是数组+链表+红黑树 当链表元素大于8 更换为红黑树、当缩减元素小于6更换为链表
默认数组长度:16
默认负载因子:0.75 在0.75负载因子下 大多数情况下是均匀分布的
处理hash冲突的方式 就是在hash数组对应的链表或者红黑树添加新的节点
计算hash使用hashCode 但是冲突的时候会使用equals去比较 判断是否添加到新节点 index=(hash(key) % 数组长度) 当计算的index相等的时候 则进行equals比较 添加进链表或者红黑树中
jdk1.7 使用hash表实现 基于冲突链表方式实现 当出现hash冲突 会在在对应的冲突链表中增加一个节点 在迭代的时候 会遍历hashtable
和冲突链表
初始容量(inital capacity) 和负载系数(load factor)影响hashMap性能
初始容量影响hashTable的大小 负载系数来指定自动扩容的临界值
当 节点数量 > 初始容量*负载因子 会触发hashMap自动扩容 这里是大于 举例 如果要插入N条数据 不触发自动扩容 需要
初始容量*负载因子+1 = N

jdk8及其之后主要是在冲突链表元素超过8的时候 会转换为红黑树 当元素从超过8减少少于6会转换为链表
参考 java.util.HashMap.TREEIFY_THRESHOLD java.util.HashMap.UNTREEIFY_THRESHOLD 变量
扩容
jdk1.7: 建立一个新数组 把旧数组所有的元素 经过hash计算重新分配到新数组中 JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置 jdk1.8: 建立新数组 长度为原数组的2倍(2n) 那么原来的元素要么在原index要么是原来的index+n (只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成"原索引+oldCap")其他关联子类
- HashMap
基于数组作为hash bucket - LinkedHashMap
记录key顺序的hashmap - TreeMap: key排序的map
- ConcurrentHashMap: 多线程安全的hashMap实现
- HashMap
线程安全的Hashmap有哪些
- HashTable
历史遗留集合 在需要考虑并发情况下的hashmap 直接使用concurrentHashMap - ConcurrentHashMap
jdk1.7使用锁分段 Segment
jdk1.8使用cas+synchronized
- HashTable
# stream集合常用操作符
基本上真正常用的 就map flatmap filter collect summary skip reduce findAny
# stream和parallelStream
parallelStream 是多线程并发处理 但是这个默认情况是使用jvm识别的核心数 性能并不高
而且限制颇多
如果遇到非要并发处理 建议还是使用线程池+自定义task 来做 可以更加精细的控制并发
# list
# linkedList 和 arrayList 区别
实现的不同 linkedList基于双向链表实现 方便插入和删除元素 顺序访问速度快 arrayList基于动态数组在插入的时候 需要移动元素
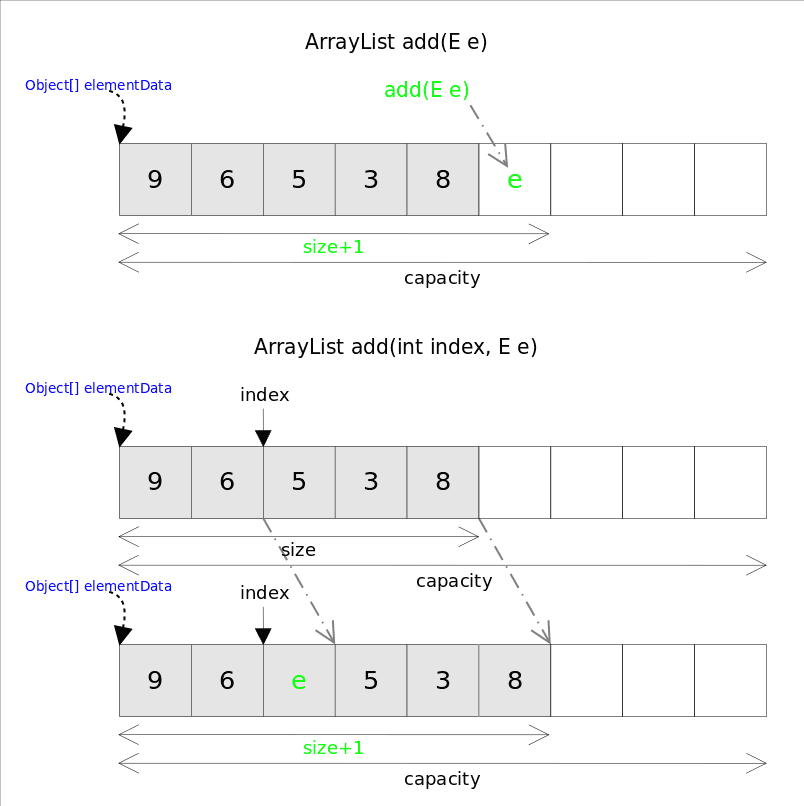
# arrayList 扩容机制
原理: 向数组添加元素会检测是否超出当前数组长度 超出了 会通过 ensureCapacity()去扩容
数组扩容讲老数组元素复制到新数组并且扩充容量为原来的1.5倍
# arrayList Fail-Fast机制
arrayList采用快速失败机制 通过记录modCount参数面对并发修改的时候 会快速失败
# 并发处理
# volatile 关键字
强制cpu读取主存 不从l1 l2 l3之类的cpu缓存中读写数据 保证volatile修饰的内容一致性
JVM内存屏障插入策略:
每个volatile写操作的前面插入一个StoreStore屏障
在每个volatile读操作的后面插入一个LoadStore屏障
# juc包详解
juc=java.util.concurrent
参考文档: https://segmentfault.com/a/1190000015558984
# 锁框架
java.util.concurrent.locks包下得类
主要就是各种锁 如 ReentrantLock
# 原子类框架
java.util.concurrent.atomic包下的类
提供一些线程安全类的基础数据类型 如AtomicInteger 通过无锁算法达到线程安全
# 同步器框架
java.util.concurrent包下有部分是同步器
| 名称 | 功能 | 备注 |
|---|---|---|
| CountDownLatch | 倒数计数器,构造时设定计数值 当计数值归0 所有阻塞线程恢复执行 内部实现aqs框架 | 设定一个数字n 每一个线程过来n-1 直到n=1 恢复所有阻塞线程 |
| CyclicBarrier | 循环栅栏,构造时候指定线程数,当所有线程到达栅栏后 栅栏放行,内部通过ReentrtantLock和Condition实现同步 | 设定一个阈值n 当有n个线程过来之后统一放行 |
| Semaphore | 信号量,类似令牌 控制共享资源访问的数量,内部实现aqs框架 | 标识当前资源有多少访问者 |
| Exchanger | 交换器,类似双向栅栏 用于线程之间配对和数据交换 内部根据并发情况分为 单槽交换和多槽交换 | 暂时不太理解 感觉像是个交流数据的一个地方 只是限制并发数量 |
| Phaser | 多阶段栅栏,CyclicBarrier升级版本 提供分阶段任务并发控制 支持树形结构 减少并发竞争 | ??? 应该是提供类似循环栅栏的操作 只是中间优化了针对多阶段任务的处理 |
# 集合框架
java.util.concurrent下得集合类
常用的 就是 queue 分有界无界 和一些特殊队列
经常见得 ConcurrentHashMap CopyOnWriteArrayList
# 执行器框架
java.util.concurrent下得执行器框架
线程池、future、fork/join框架
# JVM
# GC算法有哪些
参考资料: https://blog.csdn.net/weixin_42045591/article/details/80629449
引用计数:
给对象添加一个引用计数器,每过一个引用计数器值就+1,少一个引用就-1。当它的引用变为0时,该对象就不能再被使用。它的实现简单,但是不能解决互相循环引用的问题。
根搜索:
以一系列叫"GC Roots"的对象为起点开始向下搜索,走过的路径称为引用链(Reference Chain),当一个对象没有和任何引用链相连时,证明此对象是不可用的,用图论的说法是不可达的。那么它就会被判定为是可回收的对象。
标记清除:
它是现代GC算法的思想基础,分为标记和清除两个阶段:先把所有活动的对象标记出来,然后把没有被标记的对象统一清除掉。但是它有两个问题,一是效率问题,两个过程的效率都不高。二是空间问题,清除之后会产生大量不连续的内存。
复制:
复制算法是将原有的内存空间分成两块,每次只使用其中的一块。在GC时,将正在使用的内存块中的存活对象复制到未使用的那一块中,然后清除正在使用的内存块中的所有对象,并交换两块内存的角色,完成一次垃圾回收。它比标记-清除算法要高效,但不适用于存活对象较多的内存,因为复制的时候会有较多的时间消耗。它的致命缺点是会有一半的内存浪费。
标记整理:
标记整理算法适用于存活对象较多的场合,它的标记阶段和标记-清除算法中的一样。整理阶段是将所有存活的对象压缩到内存的一端,之后清理边界外所有的空间。它的效率也不高。
# java常用的gc
cms:
参考资料:
https://www.iteye.com/blog/zhanjia-2435266 cms回收的步骤 https://www.jianshu.com/p/d6441e775dd9 cms常规优化方式
1.7常用
采用内存分代
划分新生代 老年代 永久代 每次执行回收会标记 计算对象是晋升还是清理 高版本jdk已经不再使用
g1:
参考资料:https://www.cnblogs.com/yufengzhang/p/10571081.html
1.8常用
划分区域 + 内存分代
把内存划分成相同大小的区域 每个区域单一职责 可以为 新生代 老年代或者永久代
zgc:
参考资料:https://www.cnblogs.com/coderw/p/14281528.html
11常用
通过多重映射 多个虚拟地址映射一个物理地址 来实现不同回收阶段高效的gc
通过染色指针 来记录gc信息 标记信息、分代信息
读屏障 来控制并发操作的时候 等待引用对象处理
zgc流程: 初始标记--> 并发标记 对象重定位 -->再标记 --> 并发转移准备-->初始转移-->并发转移
zgc stw 只存在初始标记,再标记,初始转移。
# gc在不同场景下选择
Spring →